Posted on: April 30th, 2026 by Frank Wöhrle No Comments
Am 19. und 20. Mai findet zum 5. Mal die Quanos Connect in Nürnberg statt. Das wichtige Branchen-Event verbindet die Perspektiven von technischer Dokumentation und After-Sales & Service mit Fokus auf praxisnahe Lösungen, Cloud-Technologien, KI-gestützte Workflows und automatisierte Prozesse.
STAR Deutschland ist als Aussteller vor Ort – kommen Sie am Stand 31 vorbei: Unser Business Development Manager Hans-Jürgen Waurischk und unser Team Leader Technical Content Services René Feuchtinger freuen sich auf den Austausch mit Ihnen!
Zukunft gestalten – aus der Fachperspektive für technische Kommunikation
Mit unserer umfassenden Expertise in Schema ST 4, DITA, MadCap Flare, XML, HTML5, Adobe FrameMaker und zahlreichen weiteren Dateiformaten verstehen wir die Herausforderungen moderner Content-Erstellung und -verwaltung. Die Quanos Connect bietet uns als Spezialisten eine einzigartige Gelegenheit, über die Zukunft der technischen Kommunikation zu diskutieren und praxisnahe Lösungen für folgende Bereiche kennenzulernen:
Intelligente Content-Architekturen: Wie standardisierte Formate wie Schema ST 4 die Grundlage für skalierbare und wiederverwendbare Inhalte schaffen
KI-gestützte Content-Erstellung: Von der automatischen Generierung technischer Texte bis zur intelligenten Bildbeschreibung
Cross-Media-Publikation: Effiziente Bereitstellung von Inhalten über verschiedene Kanäle und Formate hinweg
Lokalisierungsstrategien: Wie moderne Workflows die Übersetzung und Anpassung für internationale Märkte beschleunigen
STAR – Ihr Partner für innovative technische Lösungen
Als erfahrener Dienstleister im Bereich technischer Dokumentation und Lokalisierung wissen wir, wie wichtig der Austausch mit Branchenspezialisten ist. Nutzen Sie die Gelegenheit, um aktuelle Trends und zukünftige Entwicklungen kennenzulernen, und lassen Sie sich von unseren Experten am Stand 31 beraten, wie wir Ihre technische Kommunikation zukunftsfähig gestalten können:
Aufbau von Content-Architekturen gemäß Schema ST 4 und internationalen Standards
Integration von KI-Tools in bestehende Workflows zur Effizienzsteigerung
Optimierung von Lokalisierungsprozessen durch Terminologie-Management und CAT-Tools
Automatisierung von Publikationsprozessen für Multi-Channel-Auslieferung
Kommen Sie vorbei! Wir freuen uns auf einen anregenden Austausch und neue Impulse für die gemeinsame Arbeit!
Posted on: Februar 27th, 2026 by Frank Wöhrle No Comments
Erfahren Sie, warum lokale Large Language Models (LLMs) als Geheimtipp für die technische Redaktion gehandelt werden und wie Sie mit KI ganz konkret Routineaufgaben automatisieren können.
Hat Ihr Unternehmen noch keinen wissensbasierten Chatbot im Einsatz? Möchten Sie sicherstellen, dass Ihre sensiblen Daten den Rechner nicht verlassen? Dann finden Sie hier praxisnahe Tipps für den erfolgreichen Einstieg.
Warum ein lokales LLM in der Redaktion Sinn ergibt
Ob Produktänderungen, API-Updates oder neue Features – technische Dokumentation muss oft kurzfristig angepasst werden. Genau hier punkten lokale LLMs wie Ollama:
Datenhoheit: Ihre Inhalte bleiben im Haus.
Offline-Fähigkeit: Auch ohne Internetanbindung einsatzbereit.
Kosteneffizienz: Keine laufenden Cloud-Gebühren.
Hinweis: Stimmen Sie Installation und Konfiguration unbedingt mit Ihrer IT-Security ab – Sicherheit geht vor!
Mittlerweile stehen eine Reihe von geeigneten lokalen LLM-Umgebungen zur Verfügung, mit denen sich einfache Aufgaben in der Redaktion erfüllen lassen. Wir haben uns die Plattform Ollama einmal genauer angesehen.
Ollama im Überblick – die lokale LLM-Plattform
Wer steckt dahinter?
Ollama ist eine Open-Source-Plattform zur lokalen Ausführung von Large Language Models (LLMs). Entwickelt wurde sie von Jeffrey Morgan (CEO) und Michael Chiang, den Köpfen hinter Kitematic, heute Teil von Docker.
Über 156.000 GitHub-Stars (Stand 2025) zeigen: Das Projekt wächst rasant. Unterstützt durch Y Combinator, bleibt Ollama dennoch Community-getrieben. Die Plattform ermöglicht es, verschiedene LLMs lokal auf Ihrem Rechner (Windows, MacOS, Linux) zu betreiben. Im Gegensatz zu cloudbasierten Diensten bleiben Ihre Daten in Ihrer Kontrolle.
Vorteile von Ollama
Keine Cloud-Uploads vertraulicher Daten
Einbindung vorhandener Referenzdokumente
Schnelle, wiederholbare Textgenerierung für Handbücher, API-Dokus oder Hilfen
Gemma3 – stark bei Textvorschlägen und Zusammenfassungen
Nach dem ersten Start von Ollama wird das Modell lokal geladen. Die Installation erfolgt einfach über einen Installer, die Anwendung kann dann über eine Oberfläche oder aus der CMD/Powershell-Konsole gestartet werden.
Ihr lokales LLM in wenigen Schritten startklar machen
1. Installation
Laden Sie Ollama über https://ollama.com/download herunter und folgen Sie den Installationsanweisungen. Danach begrüßt Sie das charmante Lama.
2. Herunterladen eines geeigneten Modells
Nach der Installation können Sie ein lokales Modell herunterladen, das für technische Dokumentation geeignet ist oder ein bereits installiertes Modell verwenden.
Öffnen Sie Ollama, klicken Sie auf „Download“ und wählen Sie z. B. llama3.2, gemma3:4b oder mistral.
Alternativ können Sie über die Konsole in Windows (CMD oder Powershell) weitere Modelle herunterladen:
Verwenden Sie dazu den Befehl: ollama pull llama3:8b
Warten Sie, bis das Modell vollständig geladen ist – und schon kann’s losgehen.
Hands-on: So erstellen Sie einen neuen Abschnitt auf Basis eines Referenzdokuments
Ausgangssituation
Referenzhandbuch (z. B. Word oder PDF) mit älterer Version der Dokumentation liegt vor.
Neue Features oder geänderte Technologie, die eine Überarbeitung oder Neuauflage des Dokuments erforderlich machen.
So geht’s: Handbuch effizient aktualisieren – mit lokaler Unterstützung
Content-Reuse: Analyse bestehender Referenzdokumente (PDF, DOCX) mit LLM
Strukturierung: Automatische Generierung von Überschriften, Listen und Absätzen
Terminologie-Harmonisierung: Angleichung der Fachterminologie mit gezieltem Prompt
Praktische Tipps – Prompt Engineering für lokale LLMs leicht gemacht
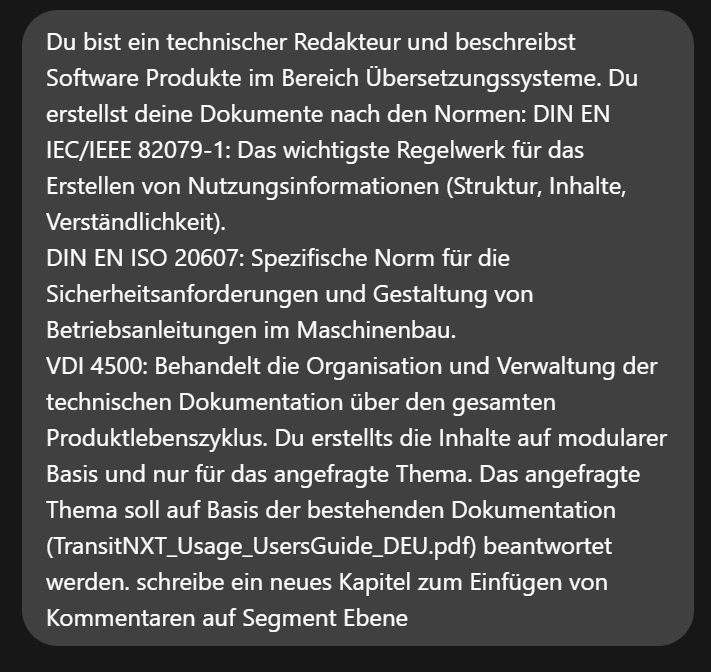
Der Schlüssel zum Erfolg liegt nicht im Modell selbst, sondern im „Prompt Engineering“. Da wir im Vergleich zu GPT-4 ein lokal recht kleines Modell verwenden, müssen wir hier sehr präzise sein. Für unseren Use Case möchten wir auf Basis eines bestehenden Handbuches die neue Funktion „Kommentare auf Segment-Ebene“ erstellen.
Prompt zur Erstellung eines Kapitels
Für unsere Anfrage haben wir uns folgenden Prompt ausgedacht. Wichtig ist hier auf das Referenzdokument zu verweisen, das Sie per Drag and Drop einfügen können.
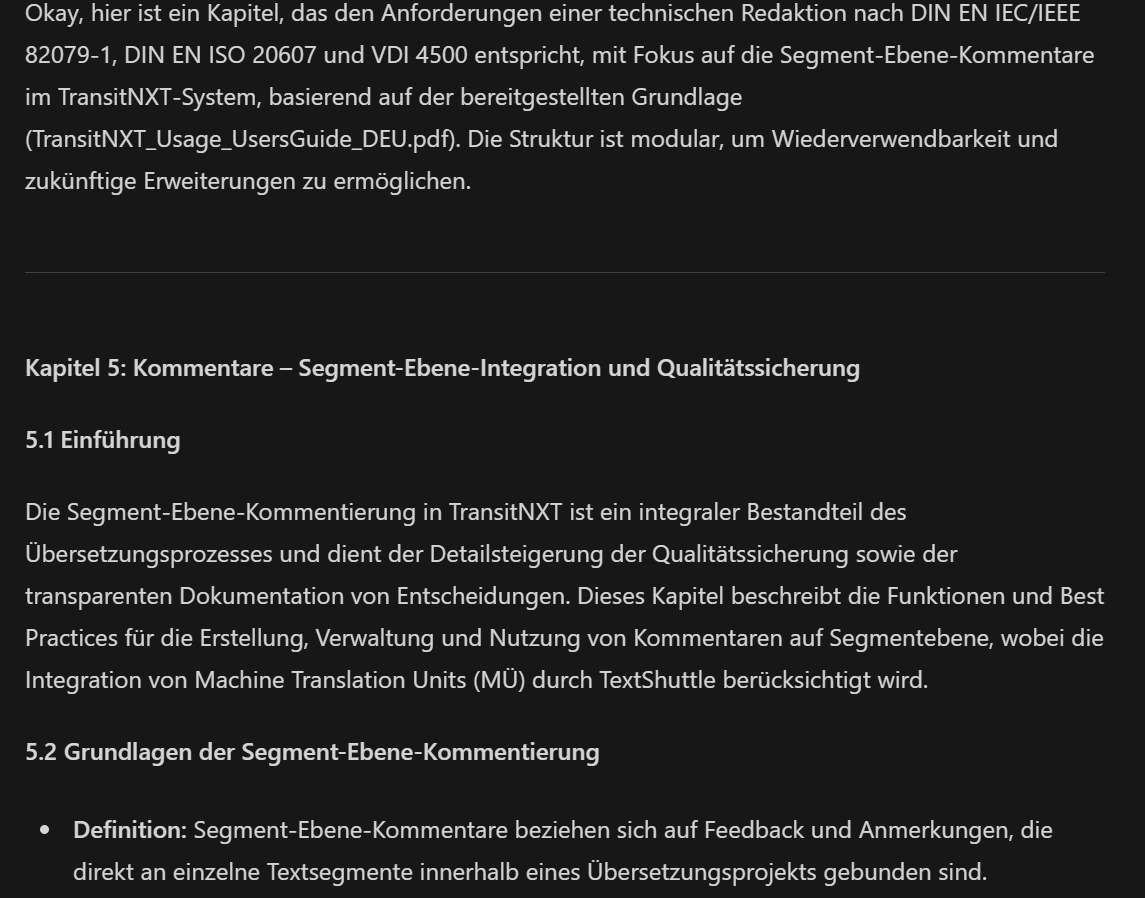
Und schon antwortet das freundliche Lama:
Beispiel-Prompts für nützliche weitere Anfragen
# Zusammenfassung des Inhalts „Fasse den Inhalt dieser Datei in 10 Stichpunkten zusammen.“
# Erstellung eines neuen Abschnitts Modell llama3: „Erstelle einen neuen Abschnitt für das Feature ‚Batch Export‘ im Stil des Referenzdokuments. Verwende kurze, klare Sätze und eine Überschrift Ebene 3. Fokus auf Schritt-für-Schritt-Anleitung.“
# Anpassung der Formatierung „Wandle alle Schritt-Listen im folgenden Text in nummerierte Listen um. Behalte die Fachbegriffe bei, aber vereinfache die Formulierungen leicht.“
Unser Tipp: Immer das Referenzdokument mitgeben – so bleiben Stil und Struktur konsistent.
Speichern und Nachbearbeitung
Auch gute KI braucht redaktionellen Feinschliff:
Überprüfen Sie die technische Richtigkeit der generierten Inhalte.
Passen Sie die Formulierung an Ihren Redaktionsstil an.
Ergänzen Sie Screenshots oder Diagramme, falls erforderlich.
Testen Sie die beschriebenen Schritte, um ihre Korrektheit sicherzustellen.
Testen Sie verschiedene Modelle, die zu Ihren Anforderungen passen.
Fazit: Datenschutz trifft Produktivität
Lokale LLMs wie Ollama eröffnen neue Möglichkeiten für die Erstellung technischer Dokumentation – und das ganz ohne Cloudabhängigkeit. Mit präzisem Prompt-Engineering und gezielter Nachbearbeitung können Sie erhebliche Zeitersparnisse erzielen, ohne auf Datenschutz und Datenhoheit verzichten zu müssen. Probieren Sie es aus: Sie werden überrascht sein, wie schnell Sie erste Ergebnisse erzielen.
Weitere „Quick Wins“ für die Technische Redaktion
Anwendungsbereich
Beschreibung
Automatische Strukturierung
Aus langen Fließtexten werden klare Überschriften, Listen und Absätze.
Vorlagen-Erstellung
Aus einem Referenzdokument entsteht ein standardisiertes Template (z. B. konsistente Struktur für „Funktionsbeschreibung“, „Voraussetzungen“, „Beispiele“).
Sprachliche Angleichung
Alle Abschnitte werden in einen einheitlichen Stil und dieselbe Tonalität gebracht (z. B. „Du“ vs. „Sie“, Passiv vs. Aktiv).
Was Sie bei lokalen LLMs beachten sollten
Technische Limitierungen
Kontextfenster:
Problem: Große Dokumente ( > 50 Seiten) → Möglicher Informationsverlust bei der Verarbeitung durch das LLM
Lösung: Kapitelweise Verarbeitung
Hallucination-Risiko:
Problem: Fiktive technische Details in Generierung
Lösung: Prompt-Modifikation mit Restriktionen, z.B. „Ändere ausschließlich den explizit markierten Bereich.“, „Erfinde keine technischen Spezifikationen.“
Compliance
DSGVO: Konformität gewährleistet durch On-Premise-Betrieb
Sicherheitsaudit: Risikoanalyse durch IT-Security vor Implementierung durchführen
Lokale LLMs: Grenzen heute und Perspektiven für morgen
Wenn lokale Systeme an ihre Grenzen stoßen – etwa bei teamweiter Zusammenarbeit oder größeren Dokumentmengen – ist der nächste Schritt klar: eine integrierte, cloudbasierte Lösung.
Sprechen Sie uns an – wir zeigen Ihnen, wie Sie KI optimal in Ihre Redaktionsprozesse einbinden können.
Posted on: November 27th, 2025 by Frank Wöhrle No Comments
E-Learnings gelten in vielen Unternehmen als zentrale Säule der Weiterbildung – vom globalen Onboarding-Kurs bis hin zur komplexen Produktschulung. Gleichzeitig zeigen Projekte immer wieder ähnliche Herausforderungen: Inhalte, die im Ursprungsland hervorragend funktionieren, verlieren in anderen Märkten an Wirkung, werden missverstanden oder schlicht nicht genutzt. Der Grund liegt selten im didaktischen Konzept, sondern meist in der Art und Qualität der Lokalisierung.
Warum Unternehmen auf E-Learning setzen
Aus Unternehmenssicht sprechen zahlreiche Faktoren für digitale Lernformate. Mitarbeitende können flexibel lernen – unabhängig von Ort, Zeitzone und Endgerät, was geografisch verteilten Teams entgegenkommt.
E-Learnings unterstützen eigenverantwortliches, zeitlich unabhängiges Lernen: Inhalte stehen on demand zur Verfügung, ohne auf feste Schulungstermine angewiesen zu sein. Durch ihren modularen Aufbau lassen sich Lerneinheiten klar strukturieren, gezielt kombinieren und bei Bedarf schrittweise aktualisieren.
Das individuelle Lerntempo ist ein weiterer Vorteil: Mitarbeitende können komplexe Inhalte pausieren, wiederholen oder vertiefen, ohne den Lernfluss anderer zu stören. Zudem ermöglichen digitale Trainings maßgeschneiderte Lerninhalte – zugeschnitten auf Funktionen, Regionen oder Zielgruppen im Unternehmen.
Multimediale Elemente wie Videos, Animationen, interaktive Übungen oder Quizze schaffen ein reichhaltiges Lernerlebnis und erhöhen die Aufmerksamkeit. Werden Inhalte mehrsprachig angeboten, trägt dies wesentlich zur Barrierefreiheit bei und macht Lernangebote für internationale Belegschaften wirklich zugänglich.
Unterm Strich führen diese Faktoren bei gelungener Umsetzung zu gesteigerten Lernerfolgen – messbar an Wissenstransfer, Anwendung im Arbeitsalltag und reduzierten Fehlerraten.
Komplexität moderner E-Learning-Formate
In der Praxis zeigt sich schnell: E-Learnings sind deutlich komplexer als klassische Schulungsunterlagen. Ein typisches Modul umfasst Folien oder Bildschirmaufnahmen, eingebettete Videos, gesprochene Kommentare, Untertitel sowie interaktive Elemente wie Quizfragen, Gesprächssimulationen o.ä.
Für die Lokalisierung bedeutet das, dass sich zu übersetzende Inhalte nicht nur in einer Datei oder einem Format finden, sondern verteilt in Authoring-Tools wie Adobe Captivate, Articulate Storyline, Articulate Rise, iSpring, Elucidat, Lectora etc., SCORM-Paketen, Video- und Audio-Skripten sowie ggf. in externen Quellen (z.B. Kursbeschreibungen, Inhalte ggf. im Kurs verknüpfter Dateien) befinden und teilweise (Video-, Audioskripte) vor der Lokalisierung noch transkribiert werden müssen. Hinzu kommen technische Anforderungen – etwa Zeichensatzunterstützung, Platzbeschränkungen in Buttons oder die Synchronisation von Untertiteln und Voice-Overs.
Wer diese Komplexität unterschätzt, steht während des Projekts oft vor Problemen: fehlende Text-Exporte, inhaltlich ähnliche Texte in unterschiedlichen Formaten, nicht übersetzte UI-Elemente oder Videos, die nachträglich teuer bearbeitet werden müssen. Ein strukturiertes Vorgehen, das alle Bestandteile von Beginn an berücksichtigt, ist daher für einen reibungslosen Lokalisierungsprozess entscheidend.
Lernen in der Muttersprache: ein Effizienzfaktor
Aus didaktischer Perspektive ist gut belegt, dass Lerninhalte am besten verinnerlicht werden, wenn sie in der eigenen Muttersprache aufgenommen werden können. Lernende müssen dann weniger kognitive Ressourcen auf das Verstehen der Sprache verwenden und können sich stärker auf Inhalte, Zusammenhänge und Anwendung konzentrieren.
Gerade bei komplexen, sicherheitsrelevanten oder rechtlichen Themen ist dies entscheidend, um Missverständnisse und Fehlinterpretationen zu vermeiden. Auch der emotionale Zugang spielt eine Rolle: Sprache beeinflusst, wie glaubwürdig, wertschätzend und motivierend ein Training wahrgenommen wird.
Für Unternehmen bedeutet das: Selbst Mitarbeitende mit guten Fremdsprachenkenntnissen profitieren von Trainings in ihrer Muttersprache – und zwar in Form schnellerer, stabilerer Lernfortschritte. Wer diese Effekte systematisch nutzt, erhöht die Wirksamkeit globaler Lernprogramme deutlich und rechtfertigt zugleich die Investition in Lokalisierung.
Rolle professioneller Fachübersetzungen in der E-Learning-Lokalisierung
Damit E-Learnings in anderen Sprachen dasselbe Lernziel erreichen wie im Original, genügt eine reine Wort-für-Wort-Übertragung nicht. Muttersprachliche Fachübersetzer*innen verbinden sprachliche Kompetenz mit Branchenwissen und kennen die Terminologie sowie die üblichen Formulierungen im jeweiligen Fachgebiet.
Sie achten darauf, dass Fachbegriffe konsistent verwendet werden, Anweisungen klar und handlungsorientiert formuliert sind und didaktische Feinheiten erhalten bleiben. Zugleich passen sie Beispiele, Metaphern oder Referenzen an, wenn diese kulturell oder kontextuell nicht ohne Weiteres übertragbar sind.
Professionelle Übersetzung trägt damit maßgeblich dazu bei, dass Lernziele schnell erreicht werden: Inhalte werden leichter verstanden, besser erinnert und eher in die Praxis umgesetzt. Ein sauber definierter Terminologie- und Review-Prozess unterstützt zudem die unternehmensweite Konsistenz, insbesondere bei einer Vielzahl von Kursen und Sprachen.
Bedeutung professionell lokalisierter Audios und Videos
Audios und Videos sind in modernen E-Learnings zentrale Träger von Information und Motivation – und stellen besondere Anforderungen an die Lokalisierung. Sprechertexte müssen so übersetzt werden, dass sie in Tonfall, Länge und Rhythmus zum Bildmaterial passen und gleichzeitig fachlich korrekt sein.
Bei Voice-Overs kommt die Auswahl geeigneter Sprecherinnen und Sprecher bzw. einer zufriedenstellenden KI-Software hinzu, die zum Corporate Image und zur Zielgruppe passen. Neben der Stimme sind Elemente wie Sprechergeschlecht, -alter, Aussprachequalität, Dialektfärbung, evtl. Hintergrundgeräusche wie Musik etc. entscheidend, um Missverständnisse zu vermeiden und ein professionelles Gesamtbild zu vermitteln.
Essentiell sind die Vorgaben des Kunden zu gewünschter Aussprache, Umgang mit Abkürzungen, barrierefreier Sprache (Gendern) etc., da die Zufriedenheit des Auftraggebers nicht zuletzt von ihrer Umsetzung abhängt.
Untertitel wiederum müssen präzise, gut lesbar und synchron zum Gesprochenen sein; sie erfordern oft eine kondensierte, aber inhaltlich vollständige Formulierung. Nicht zuletzt können visuelle Elemente – etwa eingeblendete Texte oder UI-Screens – Anpassungen verlangen, damit sie in der Zielsprache verständlich bleiben und formal in die Gestaltung passen.
Lizenz zum E-Lernen
Last, not least sind beim Einsatz von Humanstimmen im Rahmen der Vertonung vom Kunden auch Verwendungszweck und Reichweite zu klären. Sollen die vertonten E-Learnings ausschließlich intern oder auch öffentlich verwendet werden? Ist eine Option zum gewerblichen Verkauf an Dritte geplant? Je nach Übertragungsart und Art der Medien-/Rechtenutzung kann das jeweilige Tonstudio eine Lizenzgebühr pro eingesetztem*r Sprecher oder Sprecherin verlangen. Meist geht es dabei um Pauschalgebühren mit unbegrenzter Gültigkeit.
Fazit: Lokalisierung als integraler Bestandteil der E-Learning-Strategie
E-Learning entfaltet sein volles Potenzial erst dann, wenn Inhalte sprachlich und kulturell passgenau umgesetzt sind. Unternehmen, die E-Learnings international ausrollen möchten, sind gut beraten, Lokalisierung von Beginn an als festen Bestandteil der Konzeption zu betrachten – nicht als nachgelagerten Übersetzungsschritt.
Die Kombination aus didaktisch durchdachten Kursen, muttersprachlicher Fachübersetzung und professionell lokalisierten Audio- und Videoelementen bildet die Grundlage für echte Lernerfolge in mehreren Sprachen. So werden globale Trainingsprogramme konsistent, effizient und wirksam – und erfüllen den Anspruch, Wissen weltweit zugänglich zu machen, ohne an Qualität einzubüßen.
Nehmen Sie Kontakt zu uns auf, wenn Sie erreichen wollen, dass Ihre Lerninhalte international genau die Wirkung entfalten, die Sie sich wünschen – wir sind Ihr Multiplikator!
Posted on: Oktober 30th, 2025 by Frank Wöhrle No Comments
Terminologiearbeit ist seit jeher der Schlüssel zu konsistenten und qualitativ hochwertigen Übersetzungen. Mit dem Einzug von KI und Large Language Models (LLMs) verändern sich die Übersetzungsprozesse grundlegend. Doch gerade dadurch rückt die Terminologie noch stärker in den Mittelpunkt.
„KI übersetzt doch inzwischen alles perfekt – wozu also noch Terminologiemanagement?“ Diese Frage hören wir als Sprachdienstleister immer häufiger. Doch wer einmal erlebt hat, wie ein einziger falsch übersetzter Fachbegriff eine Produktbeschreibung, ein Handbuch oder eine Marketingbotschaft entstellt, weiß: Terminologie ist kein Nebenschauplatz – sie ist das Fundament qualitativ hochwertiger Übersetzung.
In Zeiten von LLMs und generativer KI verändert sich das Wie von Terminologiearbeit. Ihr Warum bleibt aber unverändert.
Warum Terminologie das Rückgrat jeder Übersetzung ist
Terminologie ist weit mehr als ein Wörterbuch. Sie definiert, wie ein Unternehmen über seine Produkte, Dienstleistungen und Werte spricht.
Ob „Controller“, „Control Module“ oder „Control Unit“: Der richtige Begriff sorgt für Wiedererkennung, Vertrauen und rechtliche Sicherheit.
Fehlt eine gepflegte Terminologie, entstehen Inkonsistenzen. In der Praxis führt das zu:
abweichenden Übersetzungen für denselben Begriff,
erhöhtem Korrekturaufwand,
unnötigen Mehrkosten, multipliziert mit der Anzahl der Zielsprachen,
uneinheitlicher Markenkommunikation,
Missverständnissen bei Kunden oder Anwender*innen.
Gerade bei umfangreichem, mehrsprachigen Content aus den Bereichen technische Dokumentation oder Marketing ist ein durchgängiges Terminologiemanagement entscheidend, um Konsistenz und Präzision im Übersetzungsprozess zu gewährleisten.
Vom Glossar zur integrierten Lösung: Erfolgreicher Übersetzungsprozess dank Terminologie
Früher lag Terminologiearbeit oft außerhalb des eigentlichen Übersetzungsprozesses – in Form von Excel-Tabellen oder statischen Listen. Heute lässt sie sich nahtlos in Translation-Management-Systeme (TMS) integrieren. Das ermöglicht:
automatische Terminologievorschläge direkt im CAT-Tool,
Terminologieprüfung während der Übersetzung,
zentrale Pflege und Freigabeprozesse.
Damit wird Terminologie zu einem lebendigen Bestandteil des Workflows – und nicht zur nachträglichen Qualitätskontrolle.
Wie KI und LLMs Terminologiearbeit verändern
KI-Systeme und LLMs eröffnen neue Möglichkeiten, Terminologie dynamischer und intelligenter zu pflegen. Einige konkrete Anwendungen können sein:
KI-Terminologieextraktion: KI kann mehrsprachige Texte schnell analysieren, um relevante Fachbegriffe automatisch zu erkennen und als Termkandidaten vorzuschlagen. Das spart Zeit in der Erstellungsphase und hilft, bisher unberücksichtigte Terminologie zu identifizieren. Die finale Validierung bleibt jedoch Aufgabe menschlicher Expert*innen.
Aufbau Terminologie-Datenbank: Fehlen noch Übersetzungen oder eine definierte Struktur, kann generative KI den Aufbau einer Terminologiedatenbank unterstützen. Varianten und Synonyme lassen sich so effizient clustern, während Metadaten wie Kontext, grammatikalische Angaben oder Definitionsvorschläge automatisch generiert werden. Die finale Prüfung und Freigabe bleiben jedoch in menschlicher Hand.
Terminologieprüfung durch KI: Terminologiefehler aus der regelbasierten Prüfung werden an die KI geschickt und dort im Gesamtkontext unter Beachtung der terminologischen Zusatzinformationen bewertet bzw. korrigiert.
Diese neuen Ansätze machen Terminologiearbeit schneller, skalierbarer und datengetriebener. Gleichzeitig bleibt sie auf die Validierung durch Menschen angewiesen – denn KI versteht nicht automatisch Unternehmenssprache oder Markenwerte.
Grenzen und Risiken: Wenn KI Begriffe „erfindet“
So leistungsfähig LLMs sind, sie bergen auch Risiken. Denn ein KI-Modell kann:
Begriffe halluzinieren – also plausible, aber falsche Termini erzeugen.
Kundenspezifische Vorgaben übersehen, wenn diese nicht eindeutig im Prompt oder System hinterlegt sind.
Vertrauliche Terminologiedaten gefährden, wenn sie in öffentlich zugängliche Systeme eingespeist werden.
Daher gilt: KI kann unterstützen, aber nicht entscheiden. Für die Entscheidung, ob ein Begriff terminologisch korrekt, markenkonform und kontextgerecht ist, ist menschliche Expertise weiterhin unerlässlich.
Best Practices: So kombinieren wir menschliche Expertise mit KI-Power
Wir als Sprachdienstleister sehen den Mehrwert darin, Technologie sinnvoll einzusetzen – nicht blind zu automatisieren. Erfolgreiche Terminologiearbeit im KI-Zeitalter beruht auf fünf Prinzipien:
Zentralisierung: Alle Terminologiedaten gehören in eine zentrale Datenbank – nicht in verstreute Listen.
Integration: Terminologie muss direkt mit CAT-Tools verbunden sein, damit Übersetzer*innen live darauf zugreifen können.
KI als Assistenz, nicht als Ersatz: KI-Tools unterstützen bei Recherche, Extraktion und Prüfung – die finale Freigabe bleibt menschlich.
Sicherheitsbewusstsein: Sensible Terminologiedaten sollten ausschließlich in datenschutzkonformen, kontrollierten Systemen verarbeitet werden.
Künstliche Intelligenz und große Sprachmodelle verändern grundlegend, wie wir mit Sprache arbeiten – doch sie ersetzen kein Terminologiemanagement. Richtig eingesetzt, machen sie es sogar effizienter und intelligenter. Denn Terminologie ist das Sprachgedächtnis eines Unternehmens. Gerade im Zeitalter der generativen KI sind klare und gepflegte Begriffe entscheidend, damit Mensch und Maschine wirklich dieselbe Sprache sprechen.
Kontaktieren Sie uns, wenn Sie Ihre Terminologie effizient aufbauen, konsistent pflegen und KI-gestützt optimieren möchten – wir unterstützen Sie bei jedem Schritt.
Hier erfahren Sie mehr über unsere Services in Kombination mit KI für ein effizientes Terminologiemanagement.
Posted on: Oktober 7th, 2025 by Frank Wöhrle No Comments
Seien Sie herzlich willkommen!
Vom 11. bis 13. November findet die größte Tagung für Technische Kommunikation statt. Besuchen Sie uns auf der tekom im Foyer am Stand 21 und erfahren Sie mehr über unsere Sprachdienstleistungen, Enterprise-Technologien und neuesten Entwicklungen.
Ihr kostenloses Ticket zur tekom-Messe
Wir möchten Sie gerne zur tekom-Jahrestagung einladen. Füllen Sie einfach dieses Formular aus, und wir übermitteln Ihnen umgehend Ihren persönlichen Messecode für die Registrierung.
Bitte beachten Sie: Der Messecode ist nur gültig für den Besuch der Messe. Das Messeticket ist nicht gültig für den Besuch der Tagung.
STAR KI-Workshop auf der tekom
In unserem STAR-Workshop „Co-Pilot KI?! Mit KI-Unterstützung erfolgreich durch Sprach- und Übersetzungsprozesse navigieren“ am 12. November um 16:30 Uhr lernen Sie, wie Sie NMT- und LLM-Technologien effizient und nachhaltig für Sprach- und Übersetzungsprozesse einsetzen können.
Standparty am 11.11 ab 18 Uhr – Drinks, Snacks & gute Gespräche!
Wir laden Sie herzlich ein zu unserer Standparty am Di. 11.11 ab 18:00 Uhr. Kommen Sie einfach vorbei – wir freuen uns darauf, den Messetag gemeinsam mit Ihnen ausklingen zu lassen!
Wir freuen uns auf einen interessanten Austausch mit Ihnen!
Posted on: Juli 28th, 2025 by Frank Wöhrle No Comments
In weniger als 4 Monaten startet die nächste tekom-Jahrestagung in Stuttgart. Vom 11. bis 13. November findet die größte Tagung für Technische Kommunikation statt. Erfahren Sie mehr über unsere Sprachdienstleistungen, Enterprise-Technologien und neuesten Entwicklungen.
KI-Workshop von STAR
In unserem STAR-Workshop „Co-Pilot KI?! Mit KI-Unterstützung erfolgreich durch Sprach- und Übersetzungsprozesse navigieren“ am 12. November lernen Sie, wie Sie NMT- und LLM-Technologien effizient und nachhaltig für Sprach- und Übersetzungsprozesse einsetzen können.
Posted on: Juli 8th, 2025 by Frank Wöhrle No Comments
Der diesjährige MT Summit fand in Genf, Schweiz, statt und bot ein abwechslungsreiches Programm aus Tutorials, Workshops und inspirierenden Vorträgen rund um die Themen maschinelle Übersetzung (MT) und große Sprachmodelle (LLMs).
Als Platin-Sponsor war die STAR AG gemeinsam mit drei Expert*innen aus Entwicklung, Support und Vertrieb vor Ort. Außerdem besuchte Julian Hamm, Language Technology Consultant bei STAR, die einwöchige Konferenz, um das Unternehmen zu vertreten und neue Ideen sowie Impulse aus Forschung und Industrie mitzunehmen.
Passend zu den sommerlichen Temperaturen gaben Technologieanbieter und Vertreter*innen aus namhaften Unternehmen und Institutionen in Vorträgen und Poster-Sessions Einblicke in die heißesten Trends der Sprachbranche. Das engagierte Organisationsteam der Genfer Universität stellte ein vielseitiges Hauptprogramm zusammen und schuf Raum für wertvollen Austausch.
Human in the Cockpit – Mensch und Maschine geschickt kombiniert
Trotz beeindruckender Fortschritte im Bereich der generativen KI wurde auch bei diesem MT Summit klar: Ohne den Menschen geht es nicht!
An diese Philosophie knüpfte auch unsere Sponsor-Präsentation mit dem Titel Human in the Cockpit – How GenAI is shaping the localisation industry and what it means for technology and business strategies an. Diana Ballard und Julian Hamm zeigten darin, welchen Einfluss die generative KI auf die Lokalisierungsbranche hat und welche Use Cases für den KI-Einsatz besonders relevant sind.
Als langjähriger Technologie- und Übersetzungspartner kennt STAR die Anforderungen der User*innen genau und optimiert die eigenen Tools und Lösungen kontinuierlich, um sie durch smarte Integrationen zukunftssicher zu machen.
Am STAR-Stand konnten die Teilnehmer*innen die praktische Umsetzung in Live-Demos erleben und sich mit unseren Expert*innen zu verschiedenen Aspekten der KI-Nutzung austauschen. Neben der Integration von bekannten LLM-Systemen wie ChatGPT stellte das Team auch die Arbeit an kleineren lokalen Modellen vor, darunter das für die Terminologiearbeit optimierte Projekt TermFusion, das für den Betrieb keine dedizierte GPU benötigt und daher recht ressourcenarm arbeitet. Mithilfe lokaler Modelle sollen etwa die Termextraktion aus zweisprachigen Datensätzen oder die intelligente Korrektur von Terminologievorgaben ermöglicht werden. Basierend auf diesem Ansatz werden aktuell auch weitere Modelle entwickelt, die für ein effizienteres Arbeiten im Übersetzungstool sorgen sollen.
Künstliche Intelligenz in der Lokalisierung: Gekommen, um zu bleiben!
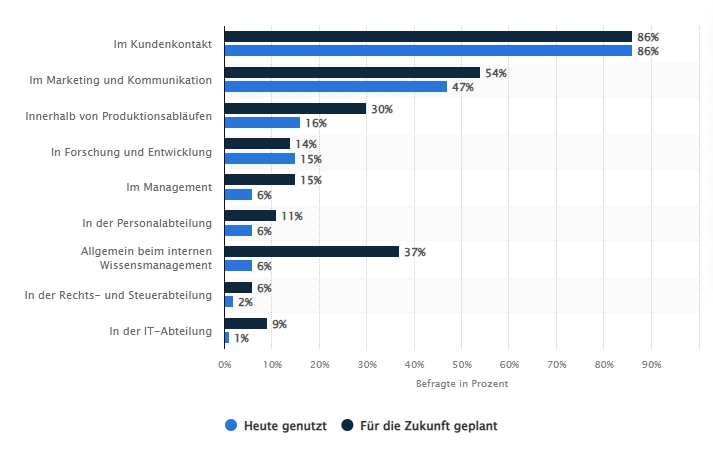
Aktuelle Statistiken zur KI-Nutzung in Unternehmen bestätigen, dass diese Entwicklungen nicht nur eine Randerscheinung sind. Vor allem Kundenkontakt, Marketing und Kommunikation sind vielversprechende Einsatzgebiete, die bereits jetzt intensiv bedient werden.
Umfrage: Einsatz von generativer Künstlicher Intelligenz in Unternehmen 2025 Veröffentlicht von Statista Research Department, 20.05.2025
Auch wenn die KI-Nutzung in der Lokalisierung noch sehr unterschiedlich ausgeprägt ist, wird deutlich: Eine One-Size-Fits-All-Lösung gibt es nicht. Denn nur, wer den Use Case kennt und die Anforderungen klar definieren kann, weiß auch, wie die Technologie sinnvoll und nachhaltig eingesetzt werden kann.
Nach fünf Tagen des intensiven Austauschs mit Vertreter*innen aus Forschung und Industrie nehmen wir sieben wichtige Erkenntnisse mit:
Die neuronale maschinelle Übersetzung (NMT) bleibt die am weitesten verbreitete Sprachtechnologie in Lokalisierungsprozessen. Zugleich werden LLMs zunehmend für die Optimierung des NMT-Outputs eingesetzt. Gerade im Forschungsbereich wird die NMT-Technologie immer stärker durch LLMs verdrängt.
Systeme und Workflows werden immer stärker darauf ausgerichtet, verschiedene Übersetzungsressourcen nahtlos miteinander zu verbinden. Translation Memories (TM) und Terminologiedatenbanken liefern wichtige übersetzungsrelevante Informationen und können skalierbar eingesetzt werden, um bessere, konsistentere Übersetzungen zu erzeugen. Eine sich mittlerweile etablierende Methode ist die sogenannte Retrieval-Augmented Generation (RAG), bei der kleinere Datenbanken als Referenz für die Texterstellung bzw. Übersetzung herangezogen werden können.
Generische KI-Modelle sind Open-Sourcen-Modellen für bestimmte Use Cases überlegen. Das Customizing in Form von Übersetzungsregeln oder automatischen Terminologieanpassungen hält Einzug in viele kommerzielle Lösungen. Diese Methode verspricht, das bisherige dedizierte Training von NMT-Systemen mittel- bis langfristig abzulösen.
Steigende Übersetzungsvolumina und der allgemeine Preisdruck erfordern den Einsatz von intelligenten Analyse-Tools, um den Mehrwert des KI-Einsatzes zu bewerten und Prozesse nachhaltig zu automatisieren. Besonders relevant sind derzeit die Integrationen von Modellen zur MT Quality Estimation sowie die Bewertung von Übersetzungen mit geeigneten Metriken, teilweise auch mit LLM-Unterstützung.
Nicht alle Aufgaben müssen zwingend von einem LLM erledigt werden. Klassische regelbasierte Ansätze, wie etwa der Einsatz von regulären Ausdrücken bei der Qualitätssicherung, haben nach wie vor ihre Berechtigung und können teilweise effizienter als LLM-basierte Mechanismen sein.
LLMs sind bereits jetzt performant genug, um Texte auf Dokumentebene analysieren und weit entfernte Zusammenhänge erkennen zu können. Die Übersetzung im CAT-Tool erfolgt aber fast immer segmentbasiert. Ist hier ein technologisches Umdenken notwendig? Der Appell ist klar: Die Verschmelzung zwischen Erstellsystemen und Übersetzungsressourcen schreitet weiter voran. Das erfordert neue und innovative Ansätze für den Umgang mit Übersetzungsressourcen und KI-Systemen.
Immer mehr Content wird von generativer KI erzeugt oder übersetzt. Dies hat auch einen Einfluss auf unsere Kultur, Sprache und unser Sozialleben, etwa durch den erhöhten Medienkonsum über Social-Media-Plattformen oder die schrittweise Verdrängung von Minderheitensprachen. Forscher*innen untersuchen derzeit Auswirkungen von generativer KI auf unser Kommunikationsverhalten.
Sie waren nicht beim MT Summit 2025 dabei und möchten noch mehr über aktuelle Trends erfahren?
Sehen Sie sich jetzt unsere Webinaraufzeichnungen an und erfahren Sie, wie Sie Übersetzung, Terminologie und Content-Erstellung nachhaltig verbessern.
Posted on: Juni 24th, 2025 by Frank Wöhrle No Comments
Wenn Sie schon einmal einen Text ins Polnische übersetzen lassen haben, selbst übersetzt haben oder anderweitig Kontakt mit slawischen Sprachen hatten, sind Sie vielleicht auf ein sprachliches Phänomen gestoßen, das im Deutschen kaum bekannt ist: den Aspekt. Im Polnischen – und auch in anderen slawischen Sprachen – sagt ein Verb nicht nur aus, was geschieht, sondern auch, ob die Handlung bereits abgeschlossen ist oder noch andauert. Für die Übersetzungsarbeit ist dieser Unterschied enorm – denn er kann darüber entscheiden, ob ein Satz die beabsichtigte oder gar eine missverständliche Wirkung erzielt.
Imperfektiver Aspekt – Wenn die Handlung „im Fluss“ ist
Der sog. imperfektive Aspekt beschreibt eine Handlung, die entweder im Moment abläuft, regelmäßig wiederholt wird oder einen allgemeinen, unbegrenzten Charakter hat. Es ist dabei unwichtig, ob die Handlung schon beendet ist oder nicht, der Fokus liegt auf dem Prozess, der Dauer oder der Wiederholung. Für deutsche Muttersprachler*innen ist dies oft eine Herausforderung, da diese Nuance im Deutschen primär durch Zeitformen oder zusätzliche Adverbien wie „regelmäßig“, „gerade“, „gewöhnlich“ o.ä. ausgedrückt wird.
Beispiel im Polnischen:
czytać (lesen – imperfektiver Aspekt)
Czytałem książkę. (Ich las/habe ein Buch gelesen. /Ich war dabei ein Buch zu lesen. – Die Handlung war im Gange oder wiederholte sich; es ist nicht gesagt, ob man schon fertig ist oder das Buch überhaupt beendet wurde. Es könnte auch bedeuten, dass ich nur anfing zu lesen, aber nicht fertig wurde.)
Codziennie czytam gazety. (Ich lese jeden Tag Zeitungen. – Hier geht es um eine Gewohnheit, etwas, das wiederholt passiert, unabhängig davon, ob die Handlung jedes Mal vollständig abgeschlossen wird.)
Der imperfektive Aspekt kann auch unvollendete oder gescheiterte Handlungen ausdrücken, bei denen der Fokus auf dem Versuch liegt.
Perfektiver Aspekt – Wenn die Handlung erledigt ist
Der perfektive Aspekt hingegen signalisiert, dass eine Handlung abgeschlossen wurde und ein Ergebnis vorliegt. Hier liegt der Fokus auf dem Abschluss der Handlung und dem Erreichen eines Ziels oder Zustands. Es geht um die einmalige, abgeschlossene Handlung, die ein Ende erreicht hat.
Beispiel im Polnischen:
przeczytać (durchlesen – perfektiver Aspekt)
Przeczytałem książkę. (Ich habe das Buch durchgelesen/fertiggelesen. – Die Handlung ist abgeschlossen, das Buch ist fertiggelesen, und das Ergebnis liegt vor.)
In Erzählungen wird so deutlich, welche Ereignisse bereits abgeschlossen sind, und die Geschichte wird vorangetrieben. In Anleitungen, Berichten oder juristischen Texten kann dieser Aspekt den Ton, den Fokus und sogar die Gesamtaussage verändern.
Ein Verb – Zwei Gesichter: Aspektpaare
Fast jedes Verb führt im Polnischen und anderen slawischen Sprachen also eine Art „Doppelleben“, da es in der imperfektiven und der perfektiven Form existiert, die beide jeweils einen bestimmten Handlungsverlauf ausdrücken. Die Bildung von Aspektpaaren erfolgt nicht nach einer festen Regel, sondern basiert auf verschiedenen morphologischen Mitteln. Dies erfordert oft das Erlernen der Paare, anstatt sich auf starre Regeln zu verlassen. Pro Verb müssen in slawischen Sprachen wie dem Polnischen also nicht eine, sondern zwei Vokabeln erlernt werden.
Gängige Methoden zur Bildung von Aspektpaaren sind:
Präfigierung: Anfügen eines Präfixes an den imperfektiven Stamm, um die Perfektivität auszudrücken. Dies ist eine der häufigsten Methoden, z. B. robić (machen/tun, imperfektiv) → zrobić (fertig machen/erledigen – perfektiv)
Robiłem obiad. (Ich kochte Mittagessen. – Die Handlung befand sich im Prozess, ich war gerade dabei, das Essen zuzubereiten.)
Zrobiłem obiad. (Ich habe das Mittagessen zubereitet/fertiggekocht. – Die Handlung ist abgeschlossen, das Mittagessen ist fertig und kann serviert werden.)
Suffixierung: Anfügen eines Suffixes oder Modifikation des Stammes. Dies kann oft subtilere Nuancen in der Bedeutung mit sich bringen. Beispiel: zamykać (schließen, imperfektiv) → zamknąć (schließen, perfektiv)
Stammveränderung: Eine Änderung des Vokals oder Konsonanten im Stamm, oft begleitet von einem Präfix. Beispiel: brać (nehmen, imperfektiv) → wziąć (nehmen, perfektiv) -> Komplette Stammveränderung: bra- → wzi-
Suppletivformen: In einigen Fällen gibt es völlig unterschiedliche Stämme für die imperfektive und perfektive Form, ähnlich wie im Deutschen bei „sein“ und „gewesen sein“. Beispiel: iść (gehen, perfektiv) → chodzić (gehen, imperfektiv) -> Unterschiedliche Stämme: iść vs. chodzić
Warum der Aspekt für Übersetzungen entscheidend ist
Wer ins Polnische übersetzt, muss mehr als nur die richtige Vokabel kennen. Es geht darum, die Perspektive der Handlung zu verstehen – läuft sie gerade, ist sie abgeschlossen, wiederholt sie sich?
Dieses sprachliche Phänomen ermöglicht dem Autor oder der Autorin eines Textes, den Fokus genau auf den Teil der Handlung zu legen, der kommuniziert werden soll – sei es der Prozess selbst oder das erreichte Ergebnis. Dies macht die slawischen Sprachen in ihrer Ausdrucksfähigkeit oft sehr präzise, erfordert aber von Nicht-Muttersprachler*innen und beim Übersetzen und Dolmetschen ein Umdenken in der Wahrnehmung von Handlungen und Zeit.
Was das für Sie bedeutet
Wenn Sie mit slawischen Sprachen arbeiten – sei es durch internationale Standorte, Kund*innen oder Zielmärkte – ist der Aspekt ein gutes Beispiel dafür, wie komplex Sprache funktioniert. Und warum maschinelle Übersetzung oft nicht ausreicht, um den richtigen Ton zu treffen.
Gute Übersetzung heißt nicht nur „Wort für Wort“ – sondern auch: Den richtigen Fokus treffen. Den Handlungsverlauf mitdenken. Einen Perspektivwechsel vollziehen.
Fazit
Der Aspekt im Polnischen (und anderen slawischen Sprachen) ist mehr als Grammatik – er ist ein zentrales Mittel, um Bedeutung zu gestalten. Ohne die korrekte Anwendung des Aspekts können Sätze missverständlich oder gar falsch interpretiert werden.
Für uns als Übersetzungsagentur ist es daher selbstverständlich, diese sprachlichen Feinheiten nicht nur zu kennen, sondern sie aktiv in unsere Arbeit einzubeziehen – damit Ihre Texte im Zielland so verstanden werden, wie Sie es beabsichtigen.
Sie möchten wissen, ob Ihre polnische Kommunikation den richtigen Ton trifft? Wir unterstützen Sie gerne.
Posted on: Februar 26th, 2025 by Frank Wöhrle No Comments
KI – Gestartet als Buzzword, danach etabliert in der Alltagssprache, mittlerweile Grundanforderung für viele Anwendungen und Prozesse. Und auch vor der Sprachenindustrie macht die Technologie nicht Halt. Seit ChatGPT wissen wir: Übersetzen kann nun auch völlig interaktiv sein. Große Sprachmodelle (Large Language Models oder LLMs) in Chatbot-Form fluten mittlerweile den Markt. Gefühlt jede Woche erscheint ein neues Modell, das sich ankündigt, die Mitstreiter in puncto Effizienz, Qualität und Zuverlässigkeit zu überbieten. Die neuronale maschinelle Übersetzung (NMT) scheint noch gar nicht so alt zu sein – und nun diskutieren wir bereits darüber, wann diese Technologie vom Markt verschwunden sein und durch generative KI ersetzt werden wird.
Die zentrale Frage lautet: Effizienter übersetzen mit KI – aber wie?
KI für gezielte Optimierung der Übersetzungsqualität
Auch wenn die Technologie im Laufe der letzten fünf Jahre einen deutlichen Sprung nach vorn gemacht hat, sind die Ergebnisse der häufig verwendeten und etablierten NMT-Systeme nicht immer ausreichend gut. Das kann verschiedene Ursachen haben:
Die gewünschte Sprachkombination wurde nicht mit ausreichend Material trainiert oder wird durch den Einsatz einer Relaissprache (oft Englisch) bedient. Dadurch kann es zu strukturellen Problemen oder Sinnfehlern kommen.
Das MT-System kennt nicht die fachgebiets- oder kundenspezifische Terminologie.
Das MT-System wurde für Inhalte verwendet, die einen hohen stilistischen Anspruch haben bzw. ein zielgruppenorientiertes Übersetzen erfordern.
Handbücher, Marketingtexte oder Inhalte mit hoher Kundensichtbarkeit erreichen durch eine reine maschinelle Übersetzung daher häufig nicht den gewünschten Qualitätsstandard. Die Optimierung der maschinellen Texte übernehmen dann Sprachprofis im Rahmen eines Post-Editings. Dabei werden maschinelle Übersetzungen genau geprüft, mit dem ausgangssprachlichen Text verglichen und bei Bedarf korrigiert.
Das CAT-Tool als zentrale Übersetzungsplattform ermöglicht ein effizientes Arbeiten und bietet durch zahlreiche Automatisierungsmöglichkeiten eine gezielte Unterstützung bei der Qualitätssicherung. Doch wo genau kommt hier KI zum Einsatz? LLMs wie ChatGPT von OpenAI sind durchaus in der Lage, Übersetzungen zu produzieren, die ähnlich wie DeepL oder Google Translate je nach Anwendungsfall einen guten Ausgangspunkt für die weitere Verarbeitung liefern.
Ein deutlicher Qualitätssprung lässt sich jedoch erreichen, wenn man die Übersetzungsanfragen durch den gezielten Einsatz von Prompts und die Zugabe von Referenzdateien verbessert. Grundvoraussetzung dafür sind aber neben einem durchdachten Prompt Engineering-Design auch validierte Übersetzungsressourcen in Form von Translation Memory- und Terminologiedatenbanken.
KI für bessere Übersetzungsressourcen
Häufig stellt man sich wie bei jeder neuen Technologie die Frage: Was kann die KI für mich tun?
Wenn Sie KI nachhaltig in Ihre Sprachprozesse integrieren möchten, sollten Sie sich aber zunächst fragen: Was kann ich für die KI tun?
Gut gepflegte Übersetzungsressourcen leisten einen entscheidenden Beitrag dazu, die Ergebnisse Ihrer KI-Lösung zu verbessern. Denken Sie zum Beispiel an das Thema Terminologie: Wenn Sie ein generisches System wie DeepL für Ihre Übersetzungsprozesse verwenden, erhalten Sie ohne die Integration eines Glossars Übersetzungen, die nicht mit Ihrer Firmenterminologie übereinstimmen.
Sie bauen Terminologie gerade erst auf und möchten nicht auf die Vorteile von MT verzichten? Nutzen Sie Sprachmodelle, um potenzielle Terminologie aus Ihren ein- oder mehrsprachigen Dokumenten zu extrahieren. Ebenso können Sie KI für die Prüfung Ihrer Translation Memory-Datenbanken einsetzen, um etwa inkonsistente Übersetzungen zu finden oder die Bereinigung bzw. Korrektur über große Datensätze hinweg zu automatisieren. Nutzen Sie dann konsequent diese Ressourcen, um die Übersetzungsqualität Ihres Sprachmodells zu erhöhen oder den Output von NMT-Systemen zu verbessern.
Co-Pilot KI? Sicher ans Ziel mit der neuen STAR-Webinar-Reihe
Sie sehen: Wir begeistern uns sehr für das Thema KI. Auch wenn wir nicht behaupten, dass sie alles neu macht. Die Technologie bietet aber viele Optimierungspotenziale, wenn man sie effizient und nachhaltig einsetzt.
Unsere Begeisterung möchten wir Ihnen natürlich nicht vorenthalten und Sie herzlich zu unserer im März startenden Webinar-Reihe „Co-Pilot KI: Neue Wege zu smarten Sprachprozessen“ einladen.
Wie genau funktioniert generative KI eigentlich? Welchen Vorteil bietet sie für die Übersetzung? Wie kann ich Sprachmodelle für die Erstellung von Produkttexten einsetzen? Kann ich meine eigene KI trainieren? Und was passiert eigentlich mit meinen Daten?
Diese und viele weiteren Fragen beantwortet unser Language Technology Consultant Julian Hamm und geht dabei auf die vielseitigen Einsatzzwecke generativer KI ein, darunter die Bereiche Übersetzung, Terminologiemanagement, Content-Erstellung oder Content Delivery. Im ersten Themenblock erwarten Sie folgende Inhalte:
Was ist generative KI, und wofür kann ich sie einsetzen?
Wie kann KI bei der Übersetzung unterstützen?
Wie kann ich KI für die Terminologiearbeit einsetzen?
Welche Vorteile bietet KI für die Content-Erstellung?
Weitere Informationen zu den Veranstaltungen sowie das Anmeldeformular finden Sie hier.
Posted on: Dezember 16th, 2024 by Frank Wöhrle No Comments
Schon wieder ist ein Jahr vorbei, und wir können selbst kaum fassen, wie schnell die Zeit verflogen ist. Ein guter Zeitpunkt, um alle wichtigen Entwicklungen aus dem KI-Jahr 2024 Revue passieren zu lassen und Ihnen einen Ausblick auf das kommende Jahr zu geben.
Seitdem OpenAI die Welt mit ChatGPT in Staunen versetzt hat, ist das Thema KI geradezu explodiert. Unternehmen drängen zunehmend darauf, KI überall dort einzusetzen, wo es möglich erscheint. Aus den zahlreichen Diskussionen und spannenden Kundenprojekten dieses Jahr haben wir zentrale Learnings und Trends in diesem Bereich erkannt.
Fünf wichtige Trends beim Einsatz von KI im Kontext der Übersetzung
Die Erwartungen an generative KI sind nach wie vor sehr hoch. Dabei werden die die Einsatzmöglichkeiten gerade in Sprachprozessen jedoch immer differenzierter betrachtet: Von der Wunschvorstellung einer Wundermaschine, die Texte perfekt erstellt, übersetzt und optimiert, hin zu einem smarten Helferlein, das gezielt bei Aufgaben unterstützt, bei denen heutzutage manuelle Aufwände anfallen. Die immer stärkere Integration großer Sprachmodelle in die Übersetzungsprozesse macht genau das möglich, indem sie gezielt und modular unterstützt, sei es bei der zweisprachigen Extraktion von Terminologie, dem Post-Editing von maschinell erstellten Übersetzungen oder der Qualitätsbewertung von mehrsprachigen Dokumenten.
Wer die Technologie effizient und nachhaltig einsetzen möchte, der benötigt auch qualitativ hochwertige, gut strukturierte Sprachressourcen, um die Sprachmodelle mit relevanten Informationen versorgen zu können. Das heißt, dass sich die jahrelange Arbeit mit Translation Memory- und Terminologieverwaltungssystemen nun gleich doppelt auszahlt. Werden diese Daten strukturiert und nachhaltig aufbereitet, können Sprachmodelle sie zur Optimierung von maschinellen Übersetzungen verwenden, etwa in Form der sogenannten Retrieval-Augmented Generation (RAG).
Das Thema Datenschutz sorgt trotz der Verabschiedung des EU AI Actim Mai 2024 nach wie vor für große Unsicherheit. Viele Unternehmen suchen nach Wegen, wie KI auf möglichst sichere Weise eingesetzt werden kann, um ihre wertvollen Daten vor Missbrauch zu schützen.
Viele Unternehmen sehen Schwierigkeiten bei der Skalierbarkeit von KI-Lösungen, sei es in Bezug auf die IT-Infrastruktur, finanzielle Ressourcen oder die Weiterbildung ihrer Mitarbeiter*innen.
Human in the Cockpit – Menschen werden stärker ins Zentrum der KI-basierten Übersetzungsworkflows rücken. Waren Übersetzer*innen bisher in Form des Human in the Loop etwa für das Post-Editing vordefinierter maschineller Übersetzungen zuständig, soll der neue Human in the Cockpit moderne Sprachtechnologien selbst interaktiv einsetzen können, um individuell Einfluss auf den Output nehmen und Prozesse effizient gestalten zu können. Durch den technologischen Wandel ändern sich auch die Anforderungen an heutige und zukünftige Sprachexpert*innen. Diese Entwicklung erkennen auch die einschlägigen Hochschulen und passen ihre Studiengänge und Kursangebote entsprechend an. So sind Prompt Engineering, Sprachtechnologien oder Informationsmanagement wichtige Schwerpunkte, die wir künftig häufiger auf den Lehrplänen zu sehen bekommen werden.
Sie finden dieses Thema spannend? Dann freuen Sie sich auf unser für Anfang 2025 geplantes STAR-Webinar. Darin informieren wir Sie über aktuelle Trends und unsere neuesten technologischen Entwicklungen.
Sie sehen gerade einen Platzhalterinhalt von Facebook. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Sie sehen gerade einen Platzhalterinhalt von Instagram. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Sie sehen gerade einen Platzhalterinhalt von Turnstile. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Sie sehen gerade einen Platzhalterinhalt von X. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.