This year’s MT Summit was held in Geneva, Switzerland, and featured a diverse programme of tutorials, workshops and inspiring presentations on the topics of machine translation (MT) and large language models (LLMs).
As a platinum sponsor of the event, STAR AG was on site together with three experts from the company’s Development, Support and Sales teams. STAR’s very own Language Technology Consultant, Julian Hamm, also attended the week-long conference to represent the company and took away new ideas and food for thought from research and industry.
While outside the temperatures were soaring, inside the very hottest trends were being presented – by technology providers and representatives from notable companies and institutions in a series of lectures and poster sessions. The dedicated organisation team from the University of Geneva put together a varied programme of events, while also setting the scene for valuable discussions.

Human in the cockpit – man and machine, a skilful combination
Despite staggering progress in the field of generative AI, this MT Summit made one thing clear: it simply doesn’t work without people!
This general philosophy was also key to our sponsored talk, entitled Human in the Cockpit – How GenAI is shaping the localisation industry and what it means for technology and business strategies. In their presentation, Diana Ballard and Julian Hamm demonstrated the influence that generative AI is exerting on the localisation industry, highlighting use cases of particular relevance for the use of AI.
As a longstanding technology and translation partner, STAR understands the precise requirements of users and continuously optimises its own tools and solutions to make them future-proof by means of integrating smart features.
Visitors to the STAR stand were able to get a hands-on experience through live demonstrations, alongside opportunities to speak to our experts about various aspects of AI in practice.
In addition to the integration of big-name LLM systems, such as ChatGPT, the team demonstrated work on smaller local models, including TermFusion, a project optimised for terminology work, which does not call for a dedicated GPU and can therefore be operated with very few resources. Local models will be used to facilitate term extraction from bilingual data records, for instance, or for the intelligent correction of terminology specifications. Using this approach as a basis, other models are currently in development to ensure working in the translation tool is even more efficient.
Artificial intelligence in localisation: it’s here to stay!
Aktuelle Statistiken zur KI-Nutzung in Unternehmen bestätigen, dass diese Entwicklungen nicht nur eine Randerscheinung sind. Vor allem Kundenkontakt, Marketing und Kommunikation sind vielversprechende Einsatzgebiete, die bereits jetzt intensiv bedient werden.
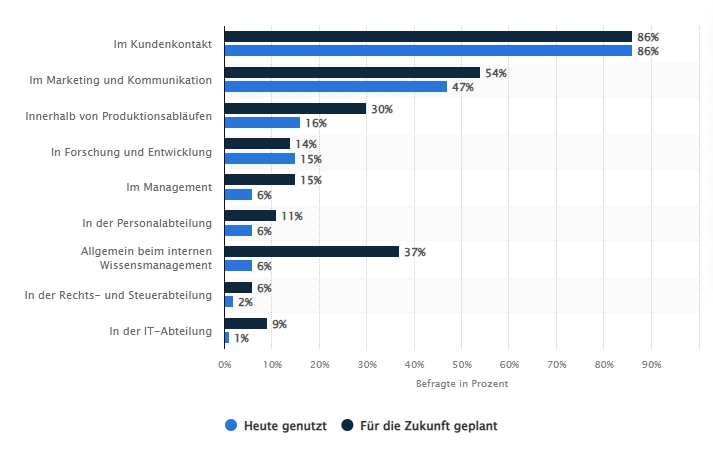
Published by the Statista Research Department, 20th May 2025
Even though the use of AI in localisation still varies a lot, one thing is plain to see: there is no one-size-fits-all solution. After all, only those familiar with the use case who can clearly define the requirements will understand how the technology can be used wisely and sustainably.
After five days of in-depth discussions with representatives from research and industry, we are taking seven important insights away with us:
- Neural machine translation (NMT) remains the most widely used language technology in localisation processes. Parallel to this, LLMs are increasingly being used to optimise NMT output. NMT technology is increasingly being displaced by LLMs, especially in the research sector.
- Systems and workflows are increasingly geared towards seamless interplay between different translation resources. Translation memories (TM) and terminology databases provide important translation-relevant information and can be scaled up or down to produce better and more consistent translations. Another method establishing itself is retrieval augmented generation (RAG), whereby smaller databases can be used as a reference point for text creation or translation.
- In certain use cases, generic AI models outperform open source models . Customisation in the form of translation rules or automatic terminology adjustments is making its way into many commercial solutions. In the medium to long term, this approach looks set to overtake the earlier method of dedicated training for NMT systems.
- Growing translation volumes alongside the overall squeezing of prices call for the use of intelligent analysis tools to evaluate the added value of using AI and automating processes for the long term. The integration of models for MT quality estimation and the evaluation of translations using suitable metrics, in some cases assisted by an LLM, are particularly relevant at the moment.
- Not all tasks necessarily have to be performed by an LLM, however. There is still a place for conventional rule-based approaches, such as the use of regular expressions in quality assurance, and in some instances, these can actually prove more efficient than LLM-based mechanisms.
- LLMs are already capable of analysing texts at a document level and identifying distant connections. In CAT tools, however, translation is almost always performed at a segment level. Does the technology need rethinking here? While it is evident that creation systems and translation resources are increasingly being merged, this calls for new and innovative approaches for handling translation resources and AI systems.
- More and more content is being created or translated by generative AI. The impact of this is felt in our culture, language and social life, for example through heightened media consumption via social media platforms or the gradual suppression of minority languages. Researchers are currently studying the effects of generative AI on our communication behaviour.
Did you miss the MT Summit 2025 and want to find out more about the latest trends?
Watch our webinar recordings now and discover how you can improve translation, terminology and content creation over the long term.