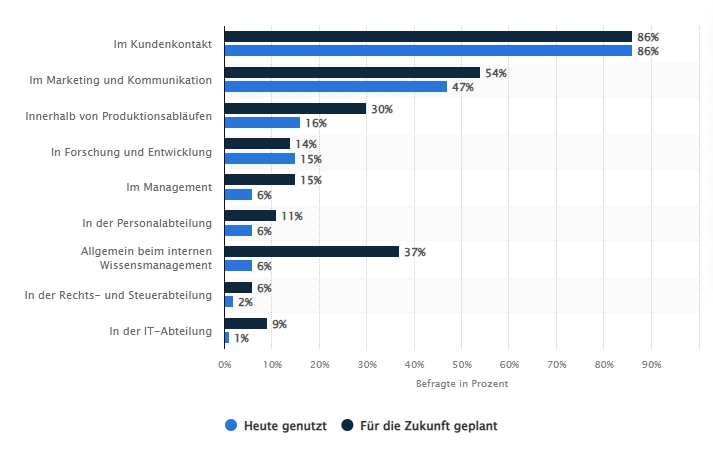
Erfahren Sie, warum lokale Large Language Models (LLMs) als Geheimtipp für die technische Redaktion gehandelt werden und wie Sie mit KI ganz konkret Routineaufgaben automatisieren können.
Hat Ihr Unternehmen noch keinen wissensbasierten Chatbot im Einsatz? Möchten Sie sicherstellen, dass Ihre sensiblen Daten den Rechner nicht verlassen? Dann finden Sie hier praxisnahe Tipps für den erfolgreichen Einstieg.
Warum ein lokales LLM in der Redaktion Sinn ergibt
Ob Produktänderungen, API-Updates oder neue Features – technische Dokumentation muss oft kurzfristig angepasst werden. Genau hier punkten lokale LLMs wie Ollama:
- Datenhoheit: Ihre Inhalte bleiben im Haus.
- Offline-Fähigkeit: Auch ohne Internetanbindung einsatzbereit.
- Kosteneffizienz: Keine laufenden Cloud-Gebühren.
Hinweis: Stimmen Sie Installation und Konfiguration unbedingt mit Ihrer IT-Security ab – Sicherheit geht vor!
Mittlerweile stehen eine Reihe von geeigneten lokalen LLM-Umgebungen zur Verfügung, mit denen sich einfache Aufgaben in der Redaktion erfüllen lassen. Wir haben uns die Plattform Ollama einmal genauer angesehen.
Ollama im Überblick – die lokale LLM-Plattform

Wer steckt dahinter?
Ollama ist eine Open-Source-Plattform zur lokalen Ausführung von Large Language Models (LLMs). Entwickelt wurde sie von Jeffrey Morgan (CEO) und Michael Chiang, den Köpfen hinter Kitematic, heute Teil von Docker.
Über 156.000 GitHub-Stars (Stand 2025) zeigen: Das Projekt wächst rasant. Unterstützt durch Y Combinator, bleibt Ollama dennoch Community-getrieben. Die Plattform ermöglicht es, verschiedene LLMs lokal auf Ihrem Rechner (Windows, MacOS, Linux) zu betreiben. Im Gegensatz zu cloudbasierten Diensten bleiben Ihre Daten in Ihrer Kontrolle.
Vorteile von Ollama
- Keine Cloud-Uploads vertraulicher Daten
- Einbindung vorhandener Referenzdokumente
- Schnelle, wiederholbare Textgenerierung für Handbücher, API-Dokus oder Hilfen
Empfohlene Modelle
- Llama3 / Llama3.1 – gute Balance aus Größe & Tempo
- Mistral – ideal für kurze, präzise Abschnitte
- Gemma3 – stark bei Textvorschlägen und Zusammenfassungen
Nach dem ersten Start von Ollama wird das Modell lokal geladen. Die Installation erfolgt einfach über einen Installer, die Anwendung kann dann über eine Oberfläche oder aus der CMD/Powershell-Konsole gestartet werden.
Ihr lokales LLM in wenigen Schritten startklar machen
1. Installation
Laden Sie Ollama über https://ollama.com/download herunter und folgen Sie den Installationsanweisungen. Danach begrüßt Sie das charmante Lama.

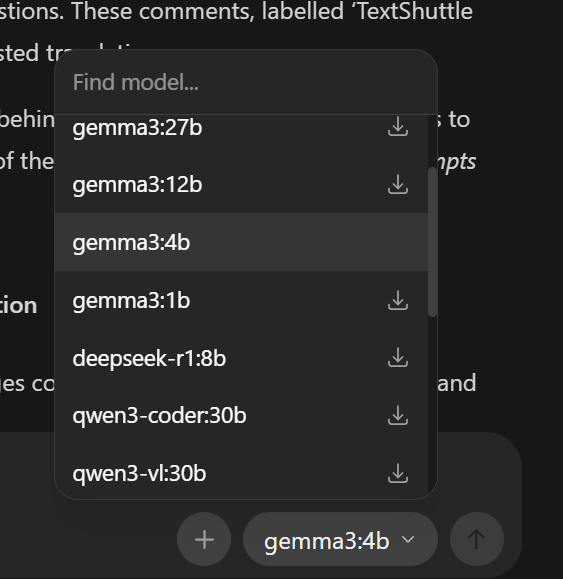
2. Herunterladen eines geeigneten Modells
Nach der Installation können Sie ein lokales Modell herunterladen, das für technische Dokumentation geeignet ist oder ein bereits installiertes Modell verwenden.
Öffnen Sie Ollama, klicken Sie auf „Download“ und wählen Sie
z. B. llama3.2, gemma3:4b oder mistral.
Alternativ können Sie über die Konsole in Windows (CMD oder Powershell) weitere Modelle herunterladen:
Verwenden Sie dazu den Befehl: ollama pull llama3:8b

Warten Sie, bis das Modell vollständig geladen ist – und schon kann’s losgehen.
Hands-on: So erstellen Sie einen neuen Abschnitt auf Basis eines Referenzdokuments
Ausgangssituation
- Referenzhandbuch (z. B. Word oder PDF) mit älterer Version der Dokumentation liegt vor.
- Neue Features oder geänderte Technologie, die eine Überarbeitung oder Neuauflage des Dokuments erforderlich machen.
So geht’s: Handbuch effizient aktualisieren – mit lokaler Unterstützung
- Content-Reuse: Analyse bestehender Referenzdokumente (PDF, DOCX) mit LLM
- Strukturierung: Automatische Generierung von Überschriften, Listen und Absätzen
- Terminologie-Harmonisierung: Angleichung der Fachterminologie mit gezieltem Prompt
Praktische Tipps – Prompt Engineering für lokale LLMs leicht gemacht
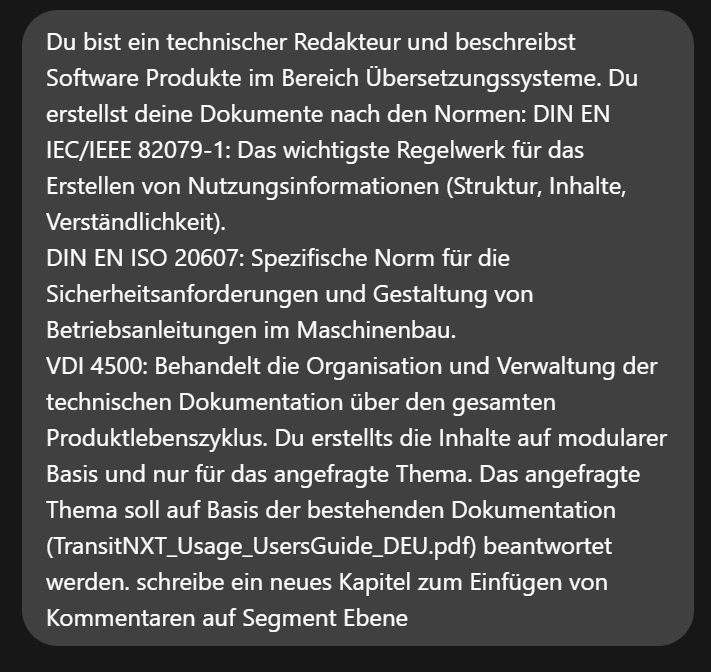
Der Schlüssel zum Erfolg liegt nicht im Modell selbst, sondern im „Prompt Engineering“. Da wir im Vergleich zu GPT-4 ein lokal recht kleines Modell verwenden, müssen wir hier sehr präzise sein. Für unseren Use Case möchten wir auf Basis eines bestehenden Handbuches die neue Funktion „Kommentare auf Segment-Ebene“ erstellen.
Prompt zur Erstellung eines Kapitels
Für unsere Anfrage haben wir uns folgenden Prompt ausgedacht. Wichtig ist hier auf das Referenzdokument zu verweisen, das Sie per Drag and Drop einfügen können.
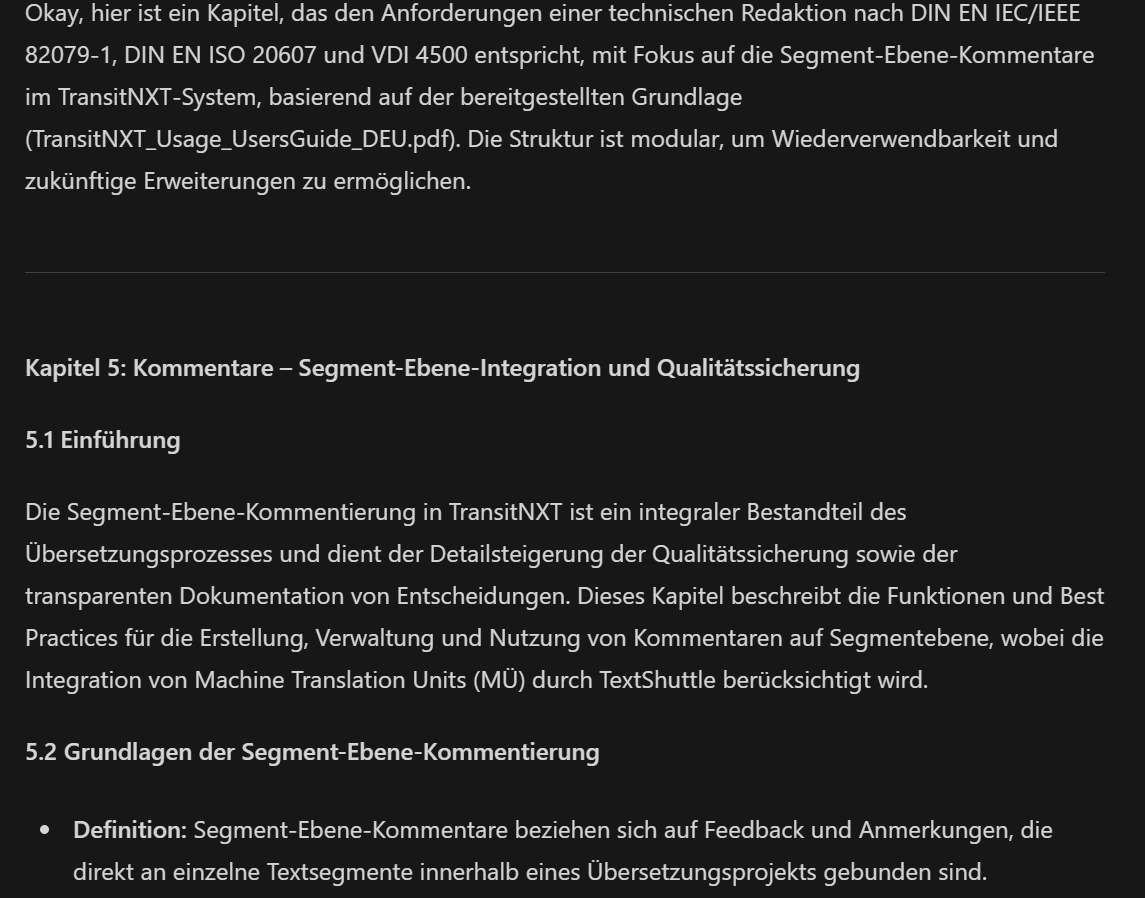
Und schon antwortet das freundliche Lama:
Beispiel-Prompts für nützliche weitere Anfragen
# Zusammenfassung des Inhalts
„Fasse den Inhalt dieser Datei in 10 Stichpunkten zusammen.“
# Erstellung eines neuen Abschnitts
Modell llama3: „Erstelle einen neuen Abschnitt für das Feature ‚Batch Export‘ im Stil des Referenzdokuments. Verwende kurze, klare Sätze und eine Überschrift Ebene 3. Fokus auf Schritt-für-Schritt-Anleitung.“
# Anpassung der Formatierung
„Wandle alle Schritt-Listen im folgenden Text in nummerierte Listen um. Behalte die Fachbegriffe bei, aber vereinfache die Formulierungen leicht.“
Unser Tipp: Immer das Referenzdokument mitgeben – so bleiben Stil und Struktur konsistent.
Speichern und Nachbearbeitung
Auch gute KI braucht redaktionellen Feinschliff:
- Überprüfen Sie die technische Richtigkeit der generierten Inhalte.
- Passen Sie die Formulierung an Ihren Redaktionsstil an.
- Ergänzen Sie Screenshots oder Diagramme, falls erforderlich.
- Testen Sie die beschriebenen Schritte, um ihre Korrektheit sicherzustellen.
- Testen Sie verschiedene Modelle, die zu Ihren Anforderungen passen.
Fazit: Datenschutz trifft Produktivität
Lokale LLMs wie Ollama eröffnen neue Möglichkeiten für die Erstellung technischer Dokumentation – und das ganz ohne Cloudabhängigkeit. Mit präzisem Prompt-Engineering und gezielter Nachbearbeitung können Sie erhebliche Zeitersparnisse erzielen, ohne auf Datenschutz und Datenhoheit verzichten zu müssen. Probieren Sie es aus: Sie werden überrascht sein, wie schnell Sie erste Ergebnisse erzielen.
Weitere „Quick Wins“ für die Technische Redaktion
| Anwendungsbereich | Beschreibung |
|---|---|
| Automatische Strukturierung | Aus langen Fließtexten werden klare Überschriften, Listen und Absätze. |
| Vorlagen-Erstellung | Aus einem Referenzdokument entsteht ein standardisiertes Template (z. B. konsistente Struktur für „Funktionsbeschreibung“, „Voraussetzungen“, „Beispiele“). |
| Sprachliche Angleichung | Alle Abschnitte werden in einen einheitlichen Stil und dieselbe Tonalität gebracht (z. B. „Du“ vs. „Sie“, Passiv vs. Aktiv). |
Was Sie bei lokalen LLMs beachten sollten
Technische Limitierungen
Kontextfenster:
- Problem: Große Dokumente ( > 50 Seiten) → Möglicher Informationsverlust bei der Verarbeitung durch das LLM
- Lösung: Kapitelweise Verarbeitung
Hallucination-Risiko:
- Problem: Fiktive technische Details in Generierung
- Lösung: Prompt-Modifikation mit Restriktionen, z.B. „Ändere ausschließlich den explizit markierten Bereich.“, „Erfinde keine technischen Spezifikationen.“
Compliance
- DSGVO: Konformität gewährleistet durch On-Premise-Betrieb
- Sicherheitsaudit: Risikoanalyse durch IT-Security vor Implementierung durchführen
Lokale LLMs: Grenzen heute und Perspektiven für morgen
Wenn lokale Systeme an ihre Grenzen stoßen – etwa bei teamweiter Zusammenarbeit oder größeren Dokumentmengen – ist der nächste Schritt klar: eine integrierte, cloudbasierte Lösung.
Sprechen Sie uns an – wir zeigen Ihnen, wie Sie KI optimal in Ihre Redaktionsprozesse einbinden können.